Recent Stories
ยกระดับ PolarDB-X HTAP ด้วยฟีเจอร์ Clustered Columnar Index (CCI)

ระบบฐานข้อมูลแบบดั้งเดิมอย่าง OLTP (Online Transaction Processing) และ OLAP (Online Analytical Processing) จะอาศัยแบ่งการอ่าน-เขียนข้อมูลแบบง่าย ๆ หรือโมเดล ETL (Extract, Transform, Load) ซึ่งทำการดึงข้อมูลจากฐานข้อมูลหลักไปยังคลังข้อมูลแบบ T+1 (ข้อมูลล่าสุด 1 วัน) เพื่อนำไปคำนวณ โดยวิธีการเหล่านี้จะมีจุดอ่อนในกรณีที่เมื่อปริมาณข้อมูลเพิ่มขึ้นอย่างรวดเร็ว ไม่ว่าจะเป็นต้นทุนที่สูงของพื้นที่จัดเก็บ การเชื่อมต่อ และการดูแลรักษา รวมถึงประสิทธิภาพแบบเรียลไทม์ต่ำ
PolarDB-X ตอบโจทย์ปัญหาดังกล่าวด้วยฟีเจอร์ใหม่ "Clustered Columnar Index" (CCI) ที่อาศัยพื้นที่จัดเก็บแบบ Object Storage โดย CCI รองรับการซิงโครไนซ์ข้อมูลแบบ Row-oriented ไปยัง Column-oriented Storage แบบเรียลไทม์ พร้อมฟีเจอร์เด่นเหล่านี้
- การผสานระหว่างการประมวลผลธุรกรรมออนไลน์ (OLTP) และการวิเคราะห์ข้อมูลแบบเรียลไทม์ ตอบโจทย์ความต้องการของแอปพลิเคชันที่ต้องการใช้งานทั้ง OLTP และ OLAP ควบคู่กัน
- การผนวกกับสถาปัตยกรรมแบบกระจายของ PolarDB รวมถึง CCI ที่รองรับการกำหนดเส้นทางอย่างชาญฉลาด และเร่งความเร็วในการคิวรี่ MPP (Massively Parallel Processing) โดยการประมวลผลจะระบุอย่างแม่นยำว่าปริมาณการจราจรนั้นเป็น TP (การประมวลผลธุรกรรม) หรือ AP (การประมวลผลเพื่อการวิเคราะห์) และสามารถเส้นทางอัจฉริยะไปยังสื่อจัดเก็บข้อมูลประเภทต่างๆ ได้อย่างเหมาะสม นอกจากนี้ ยังเปิดใช้งาน MPP โดยค่าเริ่มต้นบนเส้นทาง AP เพื่อสแกน CCI ส่งผลให้ความสามารถในการสอบถามและวิเคราะห์ข้อมูลดีขึ้น
- โมเดล Delta + Main ใช้ในการรองรับการอัปเดตแบบเรียลไทม์ในไม่กี่วินาที โดยใช้เทคโนโลยี MVCC หลายเวอร์ชัน เพื่อให้แน่ใจว่าข้อมูลที่ถูกถ่ายเก็บไว้สามารถเข้าถึงได้ทุกเวลา
PolarDB-X ให้บริการโซลูชัน HTAP ที่คุ้มค่า เรียลไทม์ และโปร่งใส ซึ่งรองรับการใช้งานร่วมกันกับ MySQL ได้อย่างเต็มรูปแบบ
ข้อกำหนดเบื้องต้น
- เฉพาะ Instance ของ Enterprise Edition เท่านั้นที่รองรับ CCI
- เวอร์ชัน Instance ต้องเป็นไปตามข้อกำหนด >= polarx-kernel_5.4.19-16989811_xcluster-20231019
สถาปัตยกรรม
การจัดเก็บข้อมูลแบบผสมระหว่างแถวและคอลัมน์
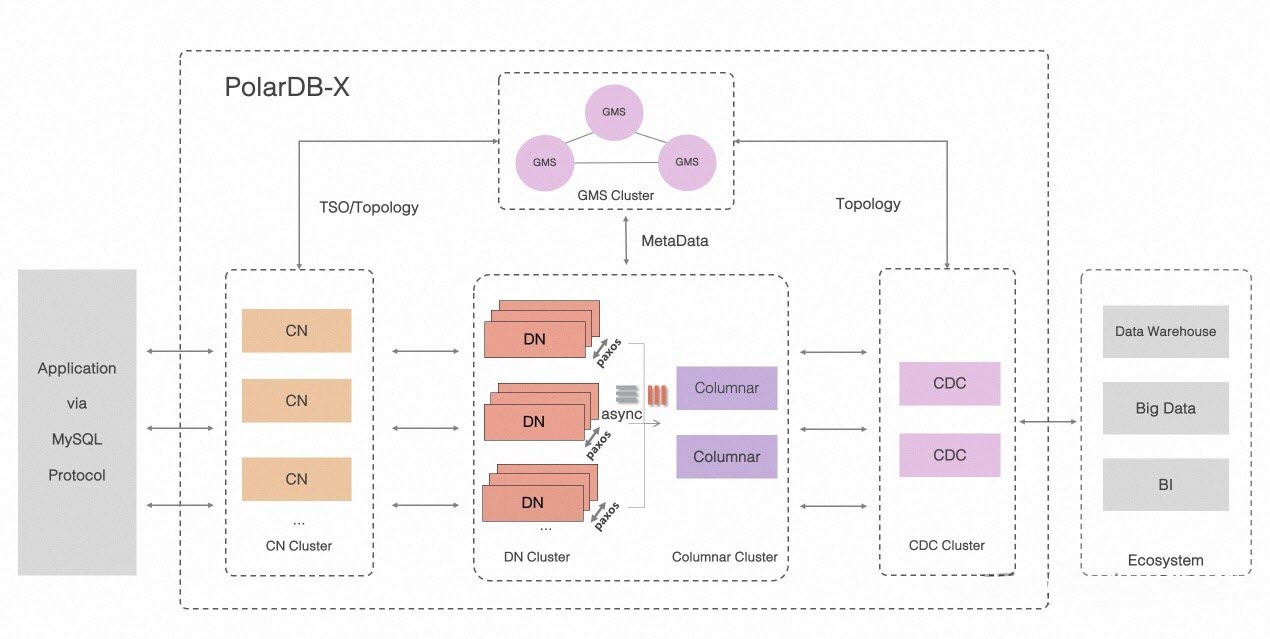
องค์ประกอบสำคัญ
- โหนดประมวลผล (Compute Node หรือ CN) เป็นโหนดที่ไม่มีการเก็บข้อมูลสถานะ ซึ่งประกอบด้วย SQL Parser, Optimizer และ Executor โดย CN รองรับการกำหนดเส้นทางแบบกระจาย, การประมวลผล, การกำหนดเวลาแบบไดนามิก, ประสานงานการทำรายการแบบกระจายด้วยโปรโตคอล 2PC และการบำรุงรักษาดัชนีรองระดับสากล นอกจากนี้ยังมีคุณสมบัติระดับองค์กร เช่น การควบคุมการใช้งาน SQL และการแบ่งโหมดเป็นสามส่วน
- โหนดจัดเก็บข้อมูล (Data Node หรือ DN) เป็นหัวใจสำคัญในการจัดเก็บข้อมูลของ PolarDB-X ซึ่งใช้รูปแบบการจัดเก็บข้อมูลแบบวางต่อเนื่อง (Row-Oriented) มีความน่าเชื่อถือสูง และมีความสอดคล้องของข้อมูลบนโปรโตคอล Paxos DN รวมถึงป้องกันการมองเห็นการทำรายการแบบกระจายผ่าน MVCC โดยใช้การประมวลผลแบบ Push-Down เพื่อให้สอดคล้องกับการประมวลผลแบบกระจาย เช่น การเลือกเฉพาะคอลัมน์ (Project), การกรองข้อมูล (Filter), การเชื่อมตาราง (Join), และการรวมข้อมูล (Agg)
- ศูนย์กลางการจัดการข้อมูลเมตา (Global Meta Service หรือ GMS) ทำหน้าที่ในการรักษาความสอดคล้องของข้อมูลทั้งระบบ รวมถึง ตาราง, สกีมา และข้อมูลสถิติ นอกจากนี้ GMS ยังรักษาความปลอดภัยของข้อมูล เช่น บัญชีผู้ใช้และสิทธิ์ และให้บริการ Timestamp Oracle (TSO) ผู้ให้บริการการประทับเวลาสำหรับอ้างอิงเวลาในระบบ
- การติดตามการเปลี่ยนแปลงของข้อมูลแบบต่อเนื่อง (Change Data Capture หรือ CDC) เป็นบริการเพิ่มเติมที่รองรับรูปแบบโปรโตคอลบันทึกไบนารีของ MySQL และการจำลองข้อมูลแบบต้นทาง-ปลายทาง ที่รองรับโปรโตคอลการจำลองข้อมูลของ MySQL
- การจัดเก็บข้อมูลแบบคอลัมน์ (Columnar Engine) ทำหน้าที่ในการติดตามการเปลี่ยนแปลงข้อมูลแบบเรียลไทม์ โดยอาศัยการประมวลผล Binary Log ร่วมกับการใช้ CCI ซึ่งเหมาะสำหรับการวิเคราะห์ข้อมูลที่ต้องการความสดใหม่เสมอ
การจัดเก็บข้อมูลแบบคอลัมน์
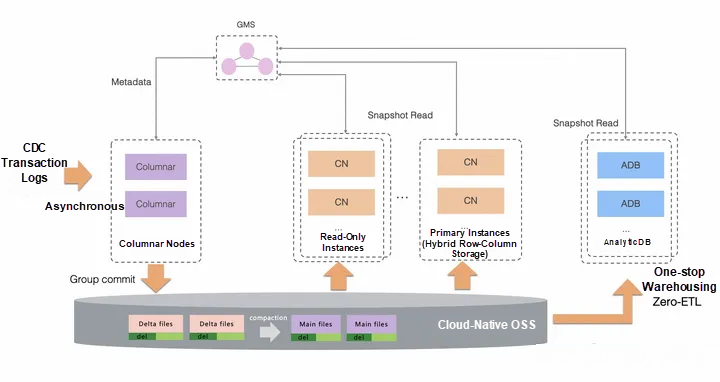
แนวคิดของสถาปัตยกรรมฐานข้อมูล
เทคโนโลยีคลาวด์เนทีฟ (Cloud Native) ได้รับความนิยมมากขึ้น ทำให้คลาวด์เนทีฟรุ่นใหม่อย่าง Snowflake และสถาปัตยกรรมฐานข้อมูล HTAP เริ่มมีบทบาทมากขึ้น ซึ่งอาจเป็นไปได้ว่า HTAP การเก็บข้อมูลแถว-คอลัมน์แบบไฮบริด จะกลายเป็นมาตรฐานของฐานข้อมูลในอนาคตของการออกแบบการจัดเก็บข้อมูลแบบคอลัมน์ในปัจจุบัน ที่ต้องคำนึงถึงต้นทุน ความสะดวกในการใช้งาน และประสิทธิภาพสูงในอนาคต
PolarDB-X มีฟีเจอร์ Clustered Columnar Index ตามการตั้งค่าเริ่มต้น ตารางที่จัดเก็บแบบแถวมีดัชนีรหัสหลัก/ดัชนีรอง โดย Clustered Columnar Index เป็นดัชนีรองแบบคอลัมน์เพิ่มเติมที่ครอบคลุมคอลัมน์ทั้งหมดของการจัดเก็บแบบแถว ทำให้ตารางสามารถจัดเก็บข้อมูลได้ทั้งแบบแถวและแบบคอลัมน์ไปพร้อมกันได้
ลักษณะของสถาปัตยกรรมข้อมูล
1. คลาวด์เนทีฟ (การแยกพื้นที่จับเก็บและต้นทุนต่ำ)
PolarDB-X CCI ใช้คลาวด์เนทีฟเป็นหลักในการจัดเก็บข้อมูล เมื่อรวมกับการบีบอัดข้อมูลแบบคอลัมน์ที่มีประสิทธิภาพสูง (สามารถบีบอัดได้ถึง 3 ถึง 5 ครั้ง) ในกรณีที่กำลังสร้างระบบจัดเก็บข้อมูลแบบผสมระหว่างแถวและคอลัมน์ของ HTAP สามารถควบคุมค่าใช้จ่ายที่อาจเกิดขึ้นได้ถึง 5 – 10% ของการจัดเก็บข้อมูลแบบแถว
โดยการจัดเก็บข้อมูลของ PolarDB-X CCI ใช้กลไกการจัดเก็บข้อมูลแบบ 2 ชั้น คือ Delta + Main (มีโครงสร้างคล้าย LSM) ร่วมกับ Marked Deletion Technology จึงทำให้มั่นใจได้ว่า OSS สามารถอัปเดตข้อมูลควบคู่กับการทำงานได้อย่างมีประสิทธิภาพ ในขณะเดียวกันการอ่านข้อมูลจาก OSS ในการจัดเก็บข้อมูลแบบคอลัมน์ CCI ใช้การแคชข้อมูลแบบหลายชั้นควบคู่กับสถิติหลายระดับ เพื่อลดการเข้าถึง OSS ระยะไกลที่ไม่จำเป็นให้น้อยที่สุด
2. เทคโนโลยีการกระจายข้อมูล (Linear Scalability)
โดยฐานข้อมูลแบบกระจายดั้งเดิมจะใช้การจำลองข้อมูลหลายสำเนา เช่น Paxos หรือ Raft ในการสร้างระบบจัดเก็บข้อมูลแบบคอลัมน์ อย่างไรก็ตามการคิวรี่ข้อมูลของ OLTP และ OLAP มีความต้องการของทรัพยากรที่แตกต่างกัน ส่งผลให้ขีดความสามารถในการขยายเชิงเส้นของ TP และ AP มีข้อกำจัด เนื่องจากนโยบายการแบ่งพาร์ทิชันที่มีความสมดุลและการขยายระหว่างรุ่นที่แตกต่างกัน
3. การออกแบบระบบฐานข้อมูลที่แยกการประมวลผลการอ่านและการเขียนข้อมูลออกจากกัน (Serverless & Pay by Read)
องค์ประกอบของ PolarDB-X CCI ใช้สถาปัตยกรรมแบบแยกการอ่านและเขียน ดังนั้น PolarDB-X CCI จึงมีการอ่านและเขียนข้อมูลแบบคอลัมน์ โดยโหนดเขียนของการจัดเก็บแบบคอลัมน์ (โหนดคอลัมน์) เป็นแบบมีสถานะ ซึ่งจะไม่มีการส่งคำขอไปยังภายนอก แต่จะทำการรวมกลุ่มข้อมูล CCI โดยใช้กลุ่มคำสั่งคอมมิทแทน ในขณะที่โหนดอ่านของการจัดเก็บแบบคอลัมน์ (CN) เป็นแบบไร้สถานะ จะได้รับเมทาดาต้าของการจัดเก็บแบบคอลัมน์จากโหนด GMS และเข้าถึงข้อมูล CCI บน OSS โดยตรง
4. การจัดเก็บข้อมูลที่ผสมระหว่างแบบแถวและคอลัมน์ (ใช้งานง่าย สามารถทำงานร่วมกับ SQL Engine แบบเวกเตอร์)
PolarDB-X ได้นำเครื่องมือการประมวลผล SQL ที่พัฒนาโดย CN มาใช้ใหม่ ในการอ่านข้อมูลที่เก็บแบบคอลัมน์ได้อย่างสมบูรณ์ พร้อมทั้งระบบปรับแต่งต้นทุนที่ออกแบบมาสำหรับการใช้งานร่วมกันระหว่างฐานข้อมูลแบบแถวและแบบคอลัมน์ โดยระบบจะทำการวิเคราะห์เส้นทางการเข้าถึงข้อมูลอย่างชาญฉลาด ซึ่งจะพิจารณาจากต้นทุนเป็นหลัก เช่น หากคิวรีข้อมูลประเภท OLTP (เน้นธุรกรรมออนไลน์) ระบบจะส่งต่อข้อมูลไปยังคิวรีแบบแถว แต่ถ้าเป็นคิวรีประเภท OLAP (เน้นวิเคราะห์ข้อมูล) ระบบจะส่งต่อข้อมูลไปยังคิวรีแบบคอลัมน์ นอกจากนี้ระบบยังรองรับการเข้าถึงข้อมูลทั้งแบบแถวและแบบคอลัมน์ได้โดยตรงที่ระดับ Operator ของ SQL ด้วยฟีเจอร์ของ HTAP ทั้งหมดถูกนำมาใช้ในการรองรับการเข้าถึงเครื่องมือประมวลผล SQL
PolarDB-X ใช้การประมวลผลแบบเวกเตอร์ได้อย่างเต็มรูปแบบ โดย TableScan จะทำการอ่านข้อมูลจากที่เก็บข้อมูลแบบคอลัมน์ และใช้โครงสร้างข้อมูลแบบคอลัมน์ชังค์ (Columnar Chunks) ในการคำนวณ Operator ต่าง ๆ ยังคงใช้โครงสร้างข้อมูลแบบคอลัมน์ชังค์ (Columnar Chunks) ที่เก็บในหน่วยความจำ เพื่อปรับปรุงประสิทธิภาพการค้นหาโดยการใช้เวกเตอร์จาก End to End นอกจากนี้ TableScan ในการจัดเก็บข้อมูลแบบแถวจะถูกแปลงข้อมูลเป็นแบบคอลัมน์ชังค์ (Columnar Chunks) โดยอัตโนมัติ เพื่อให้สามารถทำการค้นหาข้อมูลได้ทั้งแบบแถวและแบบคอลัมน์โดยใช้โครงสร้างข้อมูลแบบเดียวกัน
5. คลังข้อมูลที่รวมทุกอย่างไว้ในที่เดียว (Zero-ETL)
คลังข้อมูลแบบเดิมจะทำการซิงโครไนซ์ข้อมูลผ่านกระบวนการ ETL ซึ่งจะมีการดึงข้อมูลจากแหล่งต่าง ๆ จากนั้นแปลงข้อมูลให้เหมาะสำหรับการวิเคราะห์ และโหลดข้อมูลเข้าสู่คลัง สำหรับการค้นหาข้อมูลของ OLAP ที่ซับซ้อนนี้จะใช้การประมวลผลแบบขนาน เช่น MPP/BSP เพื่อช่วยในการประมวลผล อย่างไรก็ตามการตอบสนองการค้นหาข้อมูลที่มีผู้เข้าใช้งานพร้อมกันจำนวนมาก เช่น การให้บริการข้อมูลที่อาจเกิดปัญหาด้านข้อจำกัดในการทำงาน ทำให้ข้อมูลย้อยกลับไปยังฐานข้อมูล OLTP พร้อมกับข้อมูล
โดย PolarDB-X ที่ร่วมกันกับ AnalyticDB ให้บริการคลังข้อมูลแบบครบวงจร โดยใช้แนวคิดการออกแบบของ Zero-ETL ในการใช้ข้อมูล CCI ชุดเดียวกัน ด้วยความสามารถของ AnalyticDB ที่รองรับการรวบรวมข้อมูลและการค้นหาความเชื่อมโยงของข้อมูลจากหลายฝ่าย เพื่อใช้ในการวิเคราะห์ข้อมูลในรูปแบบคลังข้อมูลแบบเดิมและ Data Lake ในขณะเดียวกันHTAP ของ PolarDB-X สามารถใช้ในการหลีกเลี่ยงกระบวนการ ETL ของข้อมูลแบบเดิมได้ในทุกขั้นตอน
หากลูกค้าที่มีความสนใจ Alibaba Cloud สามารถติดต่อได้ที่
บริษัท ซอฟท์เดบู จำกัด (Soft De’but Co., Ltd.)
Tel : +662-861-4600
Email : [email protected]

09/26/2568

ปฏิวัติการเชื่อมต่ออินเทอร์เน็ตด้วย Argo Smart Routing จาก Cloudflare
ในยุคดิจิทัลที่ความเร็วและเสถียรภาพของอินเทอร์เน็ตมีความสำคัญยิ่ง การที่หน้าเว็บโหลดช้า วิดีโอกระตุก หรือเกมออนไลน์มีดีเลย์ เป็นสิ่งที่ผู้ใช้ทุกคนต้องการหลีกเลี่ยง Argo Smart Routing จาก Cloudflare
ดู 999 ครั้ง

09/19/2568
ปกป้อง Public Cloud ของคุณจากภัยคุกคามขั้นสูงด้วย SonicWall NSv Series
การย้ายสู่ Public Cloud คือกลยุทธ์สำคัญขององค์กรยุคใหม่ ที่มาพร้อมกับความท้าทายด้านความปลอดภัยที่ซับซ้อน มีรายงาน SonicWall ใน Executive Brief: "4 Obstacles to Attaining Public/Private Cloud Security"
ดู 999 ครั้ง

09/12/2568
Serverless Simplified ทางลัดสู่การพัฒนาแอปยุคใหม่บน Alibaba Cloud
การพัฒนาและปรับใช้แอปพลิเคชันอย่างมีประสิทธิภาพเป็นความท้าทายสำคัญสำหรับธุรกิจดิจิทัล Serverless Computing นำเสนอโซลูชันที่ตอบโจทย์ความต้องการนี้ได้อย่างลงตัว
ดู 999 ครั้ง